An intro to Open Policy Agent (OPA)
How to Build The Right App Authorization Solution - An Intro to Open Policy Agent
- Share:

Loading
2938 Members
Determining user access to digital assets is a critical aspect of building applications due to many privacy and security requirements.
Authorization solutions need to answer a simple question: Can X (users, services) perform the action they are trying to complete? (i.e., Can the requesting user access a resource?)
While a simple question, the answer to it can be quite complex - Providing a reliable technical solution in the form of a good authorization service (That won’t need rewriting every several months) can be challenging, especially in a cloud environment.
In this article, we will:
Cover a few methods for implementing an authorization layer, their advantages, and disadvantages.
Introduce Open Policy Agent (OPA), an open-source CNCF graduate project that was chosen by many prominent players in the industry (Such as Netflix, Pinterest, and Goldman Sachs) to solve their authorization needs.
Enforcing authorization is a fundamental need for almost every product. While being critically important, it is also challenging to implement correctly. Rushing into development often leaves us with an inadequate solution that won’t hold up over time or complex code that is too hard to maintain - requiring repeated refactoring in the future.
There are various factors to consider when building an authorization layer, including its flexibility to keep up with future requirements, performance, and reliability with extensive usage.
To better understand this challenge, let’s first break down the basics:

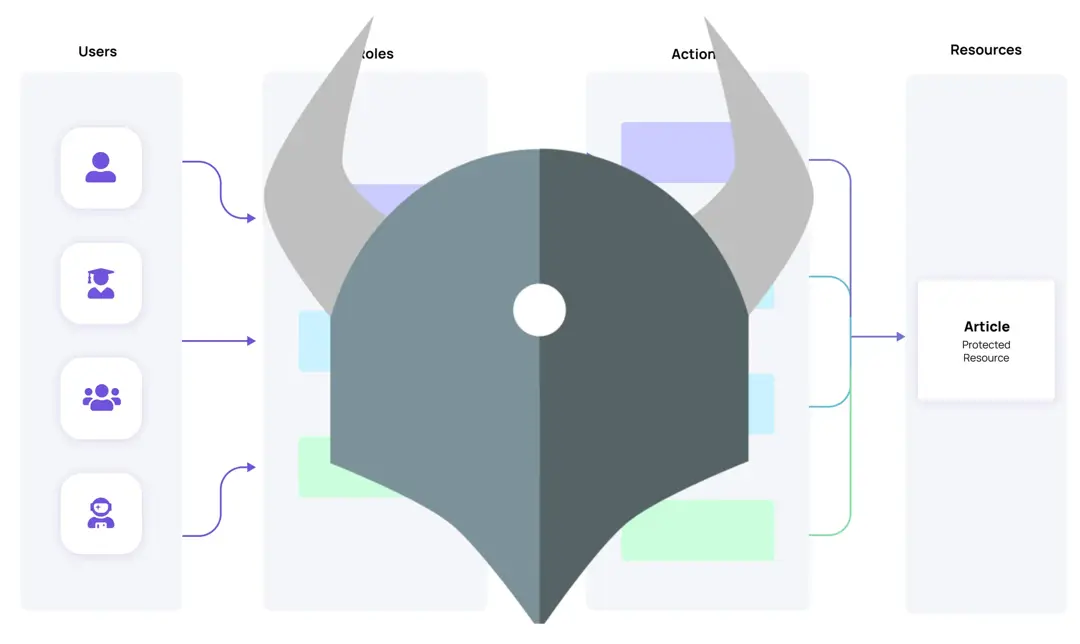
Figure 1: A simple CMS website with 3 roles, 4 actions, and 1 resource. Users assigned to roles.
On this website, there are four users who are assigned three roles - a viewer, a writer, and an editor. The roles can perform one of four actions: view, create, edit, and publish on one resource, an article. An arrow between nodes indicates that an action is supported (i.e. writer can create or edit), and a lack of an arrow indicates the user can’t perform the action (i.e. writer can’t publish).
Roles, actions, resources, and relationships are key in the world of authorization. If we generalize it, we get:
The create_article method might look like that:
function article create_article(user, content) {
//insert article creation logic here
}
Let’s look at different ways to ensure a user is authorized to create_article.
There are three main methods for implementing an authorization layer: You can build one on your own, or build one based on implementing existing elements from open source projects such as OPA or use a ready authorization as a service provider. We'll discuss the first two options:
If you choose to create your own authorization layer, you would probably start with a simple inline check:
function article create_article(user, content) {
If (user.type == types.writer) {
…
} else { return false }
}

Figure 2: Inline implementation of permissions check
Once other methods and classes need to check for permissions, the permission check will move to its own class and your method evolves:
function article create_article(user, content) {
if (permissions_service.check(user.role, action.create, article)) {
…
} else { return false }
}
A permissions service class will be born, responsible for checking if [role] has permissions to perform [action] on [resource] based on a predefined set of checks:
class permissions_service {
function boolean check(role, action, resource) { … }
}

Figure 3: Standalone service for permissions check
The advantages of this approach are:
It’s fast and straightforward to start, and as long as the code is simple, it is easy to extend.
It is easy to separate the permission logic from the function logic when things get complex. Once separated, maintaining and developing the permission microservice will not interfere with the logic.
Some immediate problems arise when implementing authorization inline:
The new microservice is tightly coupled to our requirements. As new requirements arise, a refactor will become inevitable.
Policy changes require deployment and can slow us down. Deploying for every change can become a problem, especially when an authorization-related bug happens on production and requires an immediate solution. Unfortunately, these bugs tend to appear during nighttime or on weekends.
If our codebase includes microservices written in several languages, we must write and maintain separate wrappers for accessing the authorization service.
Having a standalone microservice to handle authorization requests is a step in the right direction, but not the final step. Before we proceed to the following method, a question arises -
While roles, actions, and resources are different from one application to another, the evaluation of the authorization rules remains the same - It answers the question:
Implementation details are not relevant to this question.
In recent years, several open-source projects for general-purpose policy were created. These open-source projects are taking different implementation approaches for tackling the authorization challenge, including Google Zanzibar and OPA. In this article, we will focus on OPA.
OPA (Open Policy Agent) is an open-source project created as a general-purpose policy engine to serve any policy enforcement requirements without being dependent on implementation details - it can be used with any language and network protocol, supports any data type, and evaluates and returns answers quickly.
OPA is very efficient and built for performance - It keeps the policy and data for which it needs to evaluate the rules in the cache, and supports having multiple instances as sidecars to every microservice, thus avoiding network latency. OPA’s policy rules are written in Rego - a high-level declarative (Datalog-like) language. Examples of Rego will follow soon. Let us implement our create_article method using OPA. In order to keep the code simple to understand, we will use a code level function to wrap OPA’s check for permissions:
function article create_article(user, content) {
if (OPA_check(user.role, action.create, article)) {
…
} else { return false }
The function code will look similar to this:
function OPA_check(user, action, resource) {
const input = {
user: user,
action: action,
resource: resource,
};
return await this.client.post<OpaResult>('allow', input).then((response) => {
const decision = response.data.allow || false;
return decision;
}
}

Figure 3: Implementing permissions with OPA
The difference lies within the OPA_check logic. For OPA to evaluate the rule, it requires Rego code that defines what user is allowed to act. Then, OPA.check triggers the evaluation of the code with our input details, and an immediate answer will return.
For policy rules, OPA uses Rego, a high-level declarative language. Rego can be used to write any type of rule, including simple and complex rules with loop, function calls, and more. The Rego code for evaluating the content example will look like this:
default allow = false
allow = true {
input.type == "writer"
input.action == "create"
input.resource == "article"
}
The Rego code we just created is quite simple yet useful:
Initially, we created the identifier ‘allow’ and set its value to be ‘false’. We did this to ensure that the user will not get permissions even if one of our checks fails.
We wrote an inferred ‘if’ clause, represented by the curly brackets. We can read it like that: allow = true if all rules in the curly brackets are true.
Between the lines in the curly brackets, there is an inferred AND.
To reach the values of the variables, we used the ‘input.’ prefix and made a string comparison. You can play with our example in the rego playground here.
Rego is rather easy to read. For example, let’s add another user type, ‘intern’, that can create an article only if he is permitted (code is here):
default allow = false
allow {
input.user.type == "writer"
input.user.action == "create"
input.user.resource.type == "article"
}
allow {
input.user.type == "intern"
input.user.action == "create"
input.user.resource.type == "article"
input.user.resource.permitted == "true"
}
In Rego, we implement ‘OR’ by adding another ‘if’ clause that sets the same identifier, ‘allow’ in our case. Getting this new rule to production can happen without code changes or deployment.
Rego prefers the policy to be human-readable, even if it looks weird at first. The engine applies performance improvements to keep the rule evaluation fast - some policy rules that require low-latency results are evaluated evaluate in 1 millisecond regardless of their length. You can read more about Rego's performance here.
The advantages of using OPA as the policy microservice are:
OPA is implementation-agnostic and can support many internet protocols and programming languages simultaneously.
OPA policy code, Rego, can be changed without deployment. Moreover, Rego supports both fast and complex policy decisions.
Using Rego means that your policy is handled as code, known as policy-as-code. Having policy as code brings additional advantages: a single source of truth, policy versioning, better auditing, a transparent review process for policy changes, and more.
OPA returns results quickly as OPA stores all the policy and the data it needs in its in-memory cache.
OPA supports ABAC (Attribute-Based Access Control) fine-grained permissions and is not limited to only roles as RBAC (Role-Based Access Control.)
Using OPA as the policy engine is not perfect as well. Some of its shortcomings:
Some rules rely on real-time user data (i.e., if the user is a subscriber or not). Real-time policy updates can be very complex to achieve with OPA.
Rules that rely on multiple data sources require bundling that is not straightforward.
It can be challenging to keep all OPAs in sync when running more than one OPA instance.
There are solutions to these shortcomings of OPA in the form of open-source projects (i.e OPAL, which offers an admin layer on top of OPA and serves real-time updates to OPA).
It can be challenging to create an authorization layer in a cloud environment. While tempting, building the authorization layer yourself will require a lot of time and effort from your team, and still might result in a solution that lacks the support of fundamental features (i.e. multiple language support, distributed architecture, real-time updates, decoupling code from policy, and more). If you go down this path, chances are it will lead you to unreadable code that’s hard to maintain that will eventually require refactoring
Choosing a generic authorization policy engine will prevent future refactors while providing great flexibility, multiple languages support, decoupling between code and policy, implementation agnostic approach, and high performance.
OPA, an open-source CNCF graduate project, is used by many prominent players in the industry, such as Netflix, Pinterest, and Goldman Sachs, and is generic enough to support any policy requests. OPA supports both quick one-millisecond policy evaluations to complex policies that rely on external data sources.

Application authorization enthusiast with years of experience as a customer engineer, technical writing, and open-source community advocacy. Comunity Manager, Dev. Convention Extrovert and Meme Enthusiast.


