The first version of the agent usually ships with a shortcut. It needs to read a CRM record, comment on a Jira ticket, post a Slack update, and maybe open a support case, so the team gives it service credentials that can do all of those things. The demo works. The workflow works. The agent is useful enough that nobody wants to slow it down by asking the annoying permission questions.
Then production happens. The agent is no longer answering in a sandbox; it is calling real APIs with real customer data behind them. The CRM connector was authenticated once and never scoped to a specific user. The Jira connector can touch more projects than the workflow needs. The Slack token can post into channels the original use case never mentioned. Six months later, someone asks, "What exactly is this agent allowed to do?" and the honest answer is, "We think we know." That is not identity governance. That is archaeology.
AI identity governance is the organizational and technical framework for deciding who an AI agent is acting for, what it is allowed to do, under what context, and how that decision is enforced and recorded. It is related to agent identity security, but not identical. Agent identity security asks whether the agent can authenticate safely and avoid credential abuse. AI identity governance asks a harder question: when the agent takes an action, can you prove the authority behind that action?
Governance that works has to get four things right:
- Agents are delegated actors, not service accounts.
- Identity = human + workflow + intent.
- Every tool call needs runtime authorization.
- Audit must prove why the action was allowed.
That shift matters because agents are not just software processes. They are decision-making intermediaries. Treating them like cron jobs with nicer syntax is how you end up with a very expensive intern holding root access and no manager.
Ten governance controls
- Explicit agentic identity — Every agent action should carry the delegating human, workflow context, and declared intent.
- Deny by default at the tool boundary — If no policy explicitly allows a tool call, the call should fail.
- Layered authorization: RBAC + ABAC + ReBAC — Roles, attributes, and relationships all matter; none of them is enough alone.
- Policy-as-code with versioning and tests — Authorization rules should be reviewed, tested, promoted, and rolled back like application code.
- PDP deployed inside the customer's VPC — Authorization decisions should run close to the protected systems and data.
- OPAL for real-time policy data sync — Policy decisions are only as good as the data they see; stale authorization data is a slow-motion incident.
- Zero standing credentials — Agents should receive short-lived, scoped tokens per task, not permanent keys that slowly become folklore.
- Complete authority audit — Logs should capture delegation, consent, purpose, policy version, PDP decision, and the downstream chain.
- Guardian Agents to detect behavioral drift — Observers should watch for patterns that policy did not anticipate.
- No bypass paths — The gateway is the governed route; direct connections to tools should be blocked.
This is the forward map. Each control closes a specific failure mode, and together they move agent authorization out of tribal knowledge and into enforceable operating discipline.
Five governance failure modes
The first failure mode is tenant bleed-through. This happens when an agent has access to data from multiple tenants but the authorization decision does not bind the request to a tenant-specific context. The agent may not be malicious. It may simply retrieve the wrong record, summarize the wrong case, or use a vector-search result that crossed a boundary it never understood. "The model got confused" is a poor postmortem when the actual issue was that the tool layer allowed confusion to become access.
The second failure mode is stale delegation. A human user starts a workflow while they are active, authorized, and assigned to the relevant account. Later, that user changes teams, loses access, or leaves the company, but the agent keeps operating under the old grant. This is the identity equivalent of a badge that still opens the building after the employee has turned in their laptop. It is boring until it is catastrophic.
The third failure mode is tool-path privilege escalation. An agent may not be allowed to perform an action directly, but it discovers a sequence of permitted tool calls that produces the same outcome. It cannot export customer data, but it can query, summarize, paste into Slack, and ask another tool to format the output. Congratulations: the data was not "exported," it merely took the scenic route.
The fourth failure mode is policy fork drift. One team encodes permissions in the gateway, another adds checks inside an internal API, a third puts exceptions into a workflow engine, and the agent team keeps a YAML file because the demo needed to ship on Friday. Over time, nobody knows which rule is authoritative. This is how governance becomes theater: everyone has a policy, but no one has a source of truth.
The fifth failure mode is audit without authority. Many agent systems can show that a tool was called. Fewer can show who delegated the action, what purpose was declared, which policy allowed it, what version of that policy was active, and whether the downstream action remained inside the original authority. A log that says POST /refund happened is not an audit trail. It is a timestamp with aspirations.
Agentic identity is not an agent name
Calling something support-agent-prod does not give it an identity. That is a label. It may help you find logs or route traffic, but it says almost nothing about the authority behind a particular action. The bad pattern is naming agents as if the name itself carries permission. It does not. It is a nametag, not a passport.
Agentic identity starts with the delegating human. If an agent acts on behalf of Maya from support, the system needs to know that Maya is the source of delegated authority for this workflow. Not "support team," not "service account," not "AI assistant." A real human or accountable principal must be part of the identity envelope, because permissions, approvals, separation of duties, and revocation all depend on knowing whose authority is being exercised.
The second part is workflow context. An agent helping resolve support case CASE-1837 should not inherit broad permission to browse every case, every account, and every refund history. The workflow defines the boundary: this case, this tenant, this time window, this state, this approval chain. Without workflow context, the system cannot distinguish helpful automation from wandering curiosity.
The third part is declared intent. Intent is not a mystical reading of the model's mind; it is the stated purpose attached to the action. "Summarize this support case for the assigned agent" is different from "export all customer messages for analysis." The same underlying API may be involved, but the governance decision should change because purpose changes authorization.

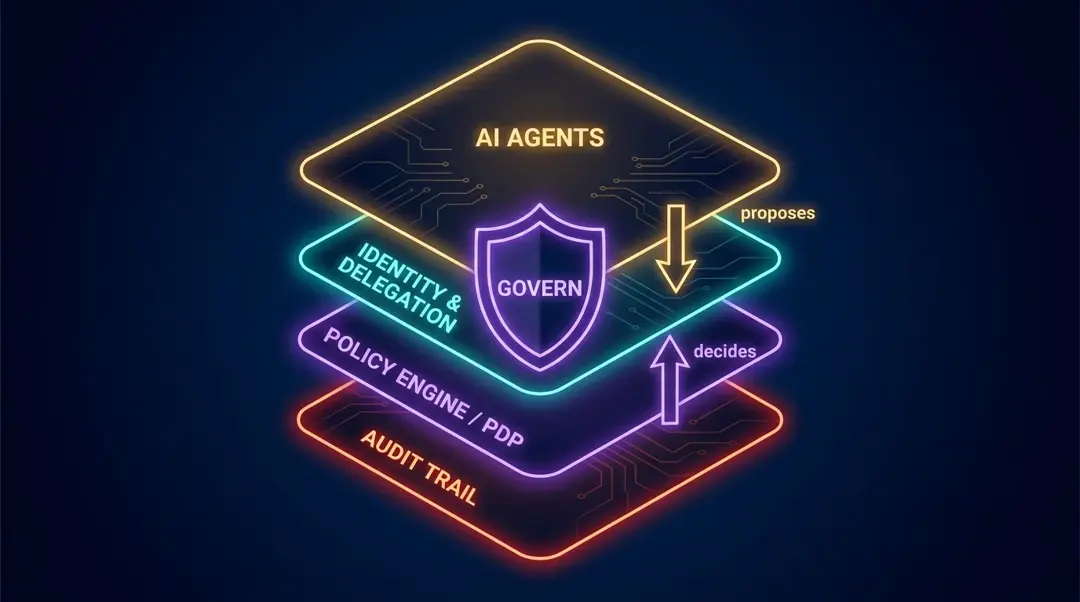
Where Permit fits: Permit MCP Gateway governs the tool boundary; the PDP decides; OPAL keeps policy and data live; audit proves authority.
This is the key distinction: agentic identity is compositional. It is not the agent alone. It is the agent acting for a human, inside a workflow, for a declared purpose, at a specific moment.
Policy-as-code is where governance stops being a meeting
Governance that lives only in diagrams eventually loses to production pressure. Someone will need an exception. Someone will hard-code a bypass. Someone will say, "We will clean this up later," which is the traditional opening ceremony for future incident response.
Policy-as-code changes the center of gravity. Authorization rules become executable, reviewable, testable artifacts. They can be versioned, checked in CI, promoted across environments, and tied to audit records. The organization still needs judgment, but the judgment turns into enforcement instead of slideware.
Here is a simplified Rego policy for a support agent:
package ai.support_agent.authz
default allow := false
# Hard deny: support agents may never export customer data.
deny["support agents cannot export customer data"] {
input.action == "export_customer_data"
}
# Helpers for shared preconditions.
workflow_active {
time.now_ns() < time.parse_rfc3339_ns(input.workflow.expires_at)
}
delegating_user_active {
input.delegating_user.status == "active"
}
same_tenant {
input.resource.tenant_id == input.workflow.tenant_id
input.delegating_user.tenant_id == input.workflow.tenant_id
}
# The agent can summarize a case only when tenant, workflow,
# delegating user, and declared intent all line up.
allow {
not deny[_]
input.agent.type == "support_agent"
input.action == "summarize_case"
input.resource.type == "support_case"
input.intent == "support_case_resolution"
same_tenant
workflow_active
delegating_user_active
input.resource.case_id == input.workflow.case_id
}
# Refunds up to $100 may proceed inside the active workflow.
allow {
not deny[_]
input.agent.type == "support_agent"
input.action == "issue_refund"
input.intent == "support_case_resolution"
same_tenant
workflow_active
delegating_user_active
input.amount <= 100
}
# Refunds over $100 require manager approval attached to the workflow.
allow {
not deny[_]
input.agent.type == "support_agent"
input.action == "issue_refund"
input.intent == "support_case_resolution"
same_tenant
workflow_active
delegating_user_active
input.amount > 100
input.workflow.manager_approval.status == "approved"
input.workflow.manager_approval.approver_role == "support_manager"
}
The summarize rule demonstrates contextual permission. The agent is not allowed to summarize any case; it can summarize the case bound to the active workflow, in the matching tenant, while acting for an active delegating user, for the declared support intent.
The export rule demonstrates a hard deny. Some actions should not become negotiable just because the model phrases the request nicely. If customer data export is outside the support agent's purpose, the policy should say so without leaving a side door open.
The refund rules demonstrate graduated authority. A small refund can proceed when the workflow context is valid, but a larger refund requires manager approval on that workflow. This is where most teams get the design backwards: they put all trust in the agent's reasoning, then try to inspect the transcript afterward. Policy should constrain the action before money moves.
Permission is not a fossil. When the workflow expires, the authority expires with it. Long-running agents need this boundary especially badly because they are often designed to keep working while everyone else has moved on to the next fire.

The model proposes; policy decides
The most useful mental model for AI identity governance is simple: the model proposes; policy decides.
The model can infer that a customer deserves a refund. It can draft the explanation, collect supporting context, and recommend the next action. But the model should not be the final authority on whether the refund is permitted. That decision belongs to a policy layer that can evaluate identity, tenant, amount, approval state, workflow status, relationship, risk, and history without being charmed by fluent text.
This is not an insult to the model. It is a separation of duties. Models are good at reasoning over messy context, but they are not authorization engines. They are probabilistic systems being asked to operate inside deterministic boundaries. Expecting the model to remember every entitlement rule is like asking a talented salesperson to also be the database lock manager. Possible in theory. Deeply silly in production.
The bad pattern is embedding permission logic in prompts: "Only issue refunds below $100 unless a manager approved it." That instruction may help guide behavior, but it is not enforcement. A prompt is advisory. A policy decision is authoritative.
The Permit.io approach
In a governed agent architecture, Permit MCP Gateway acts as the policy and routing layer between AI agents and the tools they invoke. The agent does not call CRM, Jira, Slack, billing, or internal APIs directly. It routes tool requests through a governed boundary where the request can be inspected, authorized, denied, logged, and enriched with context.
The Policy Decision Point, or PDP, should run inside the customer's VPC. That matters because authorization decisions often require sensitive context: tenant metadata, user attributes, workflow state, relationship data, approval records, and resource attributes. Pulling all of that into a distant control plane for every decision is not the shape most serious teams want. The decision point belongs close to the systems it protects.
OPAL, the Open Policy Administration Layer, keeps policy data synchronized in real time. This is what prevents the stale delegation problem from becoming normal. If a user is removed from a team, a workflow expires, or a relationship changes, the authorization layer needs to learn that quickly. Otherwise, the policy may be correct on paper and wrong at runtime, which is the least useful combination.
Permit.io's approach supports policy-as-code using Rego and Cedar, which gives teams room to express authorization in the model that fits their stack. The important point is not language preference; it is that policy becomes explicit code rather than scattered conditionals.
The gateway should be deny-by-default. If a tool call is not explicitly allowed, it should not execute. And there should be no bypass paths. If the agent can skip the gateway and call the tool directly, the gateway is not a control plane; it is a polite suggestion.

The policy lifecycle
Good governance has a lifecycle. It does not start when an incident happens and end when someone adds another if statement.
The first step is authoring. Policies should be written close to the domain they govern: support refunds, account access, sales outreach, engineering deployment, procurement approval. The policy author needs enough business context to encode the real rule, not just a vague permission label. "Support agents can access cases" is not a policy. "Support agents can summarize cases assigned to their active workflow within their tenant for support resolution" is closer.
The next step is versioning. Every policy change should produce a traceable version. When an agent takes an action, the audit record should be able to say which policy version allowed it. Without this, debugging authorization becomes folklore: someone remembers changing a rule, another person remembers a migration, and the logs sit there refusing to mediate.
Then comes testing. Authorization tests should cover allowed paths, denied paths, expired workflows, inactive users, cross-tenant access, missing approval, and tool chaining attempts. Test the uncomfortable cases. The happy path already has enough friends.
After testing, policies are deployed through controlled promotion. Development, staging, and production should not drift into three different governments. Promotion should be explicit, reviewed, and reversible.
Finally, policy and policy data must sync. Static policy without live data cannot govern dynamic agents. OPAL exists because the decision engine needs current facts: who belongs to what tenant, which workflow is active, which approval is valid, which relationship exists, and which resource attributes changed.
Zero standing credentials
Standing credentials are where agent governance quietly dies. A long-lived API key issued to an agent starts as a convenience and becomes a shadow identity. Nobody remembers who approved it. Nobody knows every path that uses it. Nobody wants to rotate it because something important may break. That is a shared credential with a poetry degree.
Zero standing credentials means agents should not hold permanent access to tools. Instead, each task should receive a short-lived, audience-bound, sender-constrained token. Short-lived means the token expires quickly. Audience-bound means it can only be used for the intended tool or service. Sender-constrained means possession alone is not enough; the token is bound to the caller or execution context.
This model forces authority to be fresh. The agent must come back to the governance layer for each meaningful action, which gives policy a chance to evaluate the current user, workflow, intent, resource, and risk. If the workflow expired five minutes ago, the next token request should fail. If the user lost access, the next action should stop. Revocation should not depend on finding a key in a secrets manager and hoping nobody copied it.
Zero standing credentials also reduce blast radius. If a token leaks, it should be narrow, short-lived, and useless outside its intended audience. The goal is not to pretend credentials will never be exposed. The goal is to make exposure boring.
Guardian Agents
Guardian Agents are observer agents that watch how other agents behave. They do not replace policy enforcement, and they should not become the sole approval authority. Their job is to detect drift, suggest policy changes, and flag unsafe or non-compliant patterns that static rules may not yet capture.
A Guardian Agent might notice that a support agent is repeatedly summarizing cases from accounts adjacent to, but not inside, its assigned workflow. It might detect that an agent is using a Slack posting tool as an indirect export channel. It might see that one workflow type generates an unusual number of manager approval requests just below a threshold. These are not always violations, but they are signals worth investigating.
The useful pattern is observation feeding governance. Guardian Agents can recommend new constraints, identify missing attributes, propose tests, or escalate suspicious sequences for review. The dangerous pattern is letting a Guardian Agent become a vague moral supervisor: "It seemed safe." That is not governance. That is vibes with logging.
Guardian Agents are strongest when paired with policy-as-code. They see behavioral patterns; policy turns accepted changes into enforceable rules. One finds the smoke. The other closes the fire door.
Audit reconstructs authority
An audit trail for AI agents should not merely record what happened. It should reconstruct why the action was allowed.
For each tool call, the audit record should capture the agent identity, delegating human, workflow ID, declared intent, resource, action, tenant, policy version, PDP decision, input attributes used in the decision, token issuance, downstream tool invocation, and resulting effect. If the agent delegated to another agent or invoked a chain of tools, the audit should preserve that chain. Authority should not dissolve just because the architecture became interesting.
This is especially important in multi-agent systems. A planner may create a task, a retriever may gather context, and an executor may write to a production system. If the executor performs the final action, the audit record needs to show how authority traveled from the delegating human through the workflow to the executor. Otherwise, the final write appears authorized only because something upstream sounded confident.
The standard to aim for is simple: a reviewer should be able to replay the decision without rerunning the model. They should see the policy, the facts, the decision, and the chain of delegation. If the explanation depends on reading a 40-message model transcript and guessing what the agent meant, the audit is not doing its job.
The ten controls revisited as operating discipline
Explicit agentic identity gives every action a real authority envelope. The agent is not just support-agent-prod; it is acting for a delegating human, inside a workflow, for a declared intent. That is the difference between accountable automation and a service account wearing a costume.
Deny-by-default at the tool boundary turns uncertainty into safety. When the authorization layer lacks enough context, the answer should be no. This can feel harsh during development, but production systems should prefer a failed tool call over an accidental data exposure. The agent can ask for more context. The customer cannot unsee another tenant's data.
Layered authorization matters because agent permissions are rarely one-dimensional. RBAC can say the delegating user is in support. ABAC can say the case belongs to the same tenant and the workflow is active. ReBAC can say the user is assigned to this account or has a relationship to this resource. Any one of these alone is too blunt; together they start to resemble the real world.
Policy-as-code creates a governance surface that engineering teams can actually operate. Rules can be reviewed, tested, diffed, deployed, and rolled back. More importantly, they stop hiding in prompts, product specs, and Slack threads. If a rule matters, it should be executable.
A PDP inside the customer's VPC keeps authorization close to sensitive data and production systems. This reduces latency, limits unnecessary data movement, and gives the customer more control over the decision path. Authorization is infrastructure, not a decorative API call.
OPAL for real-time policy data sync keeps decisions fresh. Without live data, an elegant policy can still authorize the wrong thing because it is evaluating yesterday's world. Agent systems move quickly; revocations, workflow changes, tenant updates, and relationship changes need to reach the decision layer quickly as well.
Zero standing credentials prevent agents from accumulating permanent power. Short-lived, scoped tokens force each task through a current authorization decision. This makes revocation meaningful and limits the damage from leaked or misused credentials.
Complete authority audit makes the system explainable after the fact — not in the fuzzy "the model reasoned about it" sense, but in the operational sense: here is who delegated, here is the purpose, here is the policy version, here is the PDP decision, here is the downstream chain. That is the record you need when something goes wrong.
Guardian Agents add behavioral awareness to the governance system. They watch for drift, suspicious tool sequences, and patterns that suggest the policy is too loose, too strict, or missing a category entirely. They are not a substitute for enforcement, but they are a useful early-warning system.
No bypass paths make the whole design real. If agents can call tools directly, use old tokens, or route around the gateway, every other control becomes optional. The governed route must be the only route. Otherwise, you did not build governance; you built a scenic checkpoint.
Frequently asked questions
What is AI identity governance?
AI identity governance is the framework for controlling who an AI agent acts for, what it can do, when it can do it, and how that decision is recorded. It goes beyond authentication by tying each agent action to delegated authority, workflow context, declared intent, runtime policy, and audit evidence.
How is AI identity governance different from agent identity security?
Agent identity security focuses on authenticating agents and protecting credentials. AI identity governance focuses on authorization and accountability: whether a specific action should be allowed, who delegated it, what purpose it served, and which policy approved it. Security asks whether the agent can prove what it is; governance asks whether the agent has authority to act.
What is agentic identity?
Agentic identity is the combination of the delegating human, workflow context, and declared intent behind an agent action. The agent name alone is not enough because it does not explain whose authority is being used or why the action is permitted. A governed system treats the agent as a delegated actor, not as a generic service account.
Why do AI agents need runtime authorization?
AI agents need runtime authorization because their actions depend on changing context. A user may lose access, a workflow may expire, an approval may be revoked, or a resource may move to another tenant. Runtime authorization checks the current facts before each meaningful tool call, rather than trusting permissions granted hours or months earlier.
What does "the model proposes; policy decides" mean?
"The model proposes; policy decides" means the AI model can recommend or request an action, but an external policy layer makes the authorization decision. This keeps probabilistic reasoning separate from deterministic enforcement. The model may decide a refund is reasonable, but policy decides whether that refund is allowed.
Why are standing credentials dangerous for AI agents?
Standing credentials give agents persistent access that can outlive the workflow, user, or original business purpose. Over time, these credentials become difficult to audit, rotate, and revoke. Short-lived, scoped tokens reduce blast radius and force agents to revalidate authority for each task.
What role does Permit MCP Gateway play in AI identity governance?
Permit MCP Gateway sits between AI agents and the tools they invoke, acting as the governed route for tool access. It routes tool calls through policy decisions, supports deny-by-default enforcement, and helps ensure direct bypass paths are blocked. In this model, the gateway is where agent intent meets authorization.
How do Guardian Agents improve AI governance?
Guardian Agents observe agent behavior and look for unsafe patterns, behavioral drift, and policy gaps. They can suggest policy changes, flag suspicious tool chains, and identify cases where agents are operating outside the expected workflow. They should support policy enforcement, not replace it.
What should an AI agent audit log include?
An AI agent audit log should include the delegating human, agent identity, workflow context, declared intent, resource, action, policy version, PDP decision, and downstream tool chain. The goal is to reconstruct authority, not merely prove that an API call happened. A useful audit trail explains why the action was allowed at the time it occurred.