Teams adopting coding agents keep hitting the same architectural wall: the binary problem. At first, they require human approval for everything because it feels safe. A few days later, developers are clicking "approve" for routine file writes, package installs, and test commands dozens of times per session, so they disable prompts to get work done.
That is the disable-by-noise failure mode. It starts as strict supervision, degrades into approval fatigue, and ends as effectively zero oversight. You don't get sustainable safety; you get oscillation between unusable friction and blind trust. I've seen this pattern with Cursor, Claude Code, Factory Droid, OpenCode, and custom MCP-connected agents in internal platforms.
The deeper issue is that "agent access" is usually treated like a single on/off switch. But modern agents are operational actors: they read repos, edit code, call MCP tools, open PRs, and sometimes trigger deployment-class workflows. Those actions do not belong in one risk bucket. A grep command and a production migration are not operationally equivalent.
The practical answer is to define trust levels per action and enforce them with runtime authorization policy. Autonomy levels matter, but they are only the starting configuration. If you stop there, you're just moving the binary problem into a config file.
What coding agents actually do today
Coding agents are no longer autocomplete with better branding. They execute workflows that span code, infrastructure, and business systems, often through MCP (Model Context Protocol) connectors and terminal commands. In real teams, they can touch multiple blast radii in a single run.
You can see this shift in mainstream workflows discussed around Claude Code agent loops and operational usage patterns and in platform features like Factory Droid autonomy level controls plus Factory Droid MCP configuration options. These are not toy features; they're enabling agent routines, auto mode, tool invocation, and fleet-like behavior in normal engineering operations.
Typical agent actions now include:
- Reading codebases and git history
- Editing multiple files across modules
- Running package managers and test suites
- Opening branches and PRs
- Querying Slack, tickets, docs, and internal APIs through MCP tools
- Executing deployment-adjacent commands in CI or ops contexts
That means your security model must move from "can the agent run?" to "which specific operation is allowed right now, by whom, where, and why?"
A useful taxonomy should reflect blast radius, reversibility, and potential for abuse. If an action is low-blast and easy to roll back, it can usually run with minimal friction. If it is high-blast, hard to reverse, or touches secrets or money, it needs strict controls regardless of agent quality.
The most common mistake is classifying by interface instead of outcome. Teams say "terminal is dangerous, MCP is safe" or "this server is trusted." That framing is wrong. Risk comes from what the operation does, not whether it arrived as a shell command or an MCP call.
This is why MCP tool classification should inherit from wrapped behavior. A read-docs MCP tool is read-only risk. A database-write MCP tool is privileged-write or higher. Because MCP servers usually aggregate mixed tools, per-tool authorization beats per-server authorization every time.
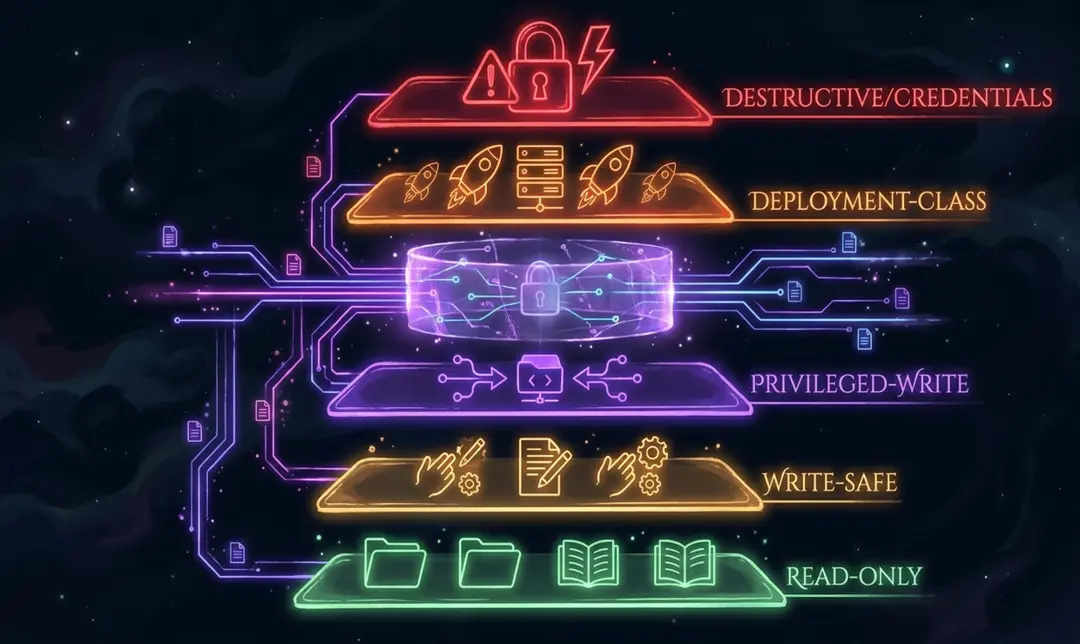
Here is the practical trust-tier model:
| Trust tier |
Risk level |
Typical actions |
Default handling |
| Read-only |
Lowest |
search files, read code, grep, list directories, fetch docs, read Slack, inspect git history |
Auto-allow in most contexts |
| Write-safe |
Low |
create files, edit code, install packages, run tests, commit changes |
Auto-allow in sandbox/dev with guardrails |
| Privileged-write |
Medium |
push to branches, open PRs, modify configs, add dependencies, write to databases |
Conditional allow (branch/env/repo constraints) |
| Deployment-class |
High |
deploy to staging/production, run migrations, scale services, send external notifications |
JIT approval and strong environment gates |
| Destructive/credentials |
Highest |
delete resources, drop databases, revoke access, rotate secrets, transfer funds, access secret stores |
Deny by default, explicit break-glass only |
This taxonomy also maps directly to command allowlist and command denylist design. Allowlists should be tier-aware, not static. Denylists should permanently block destructive/credential paths unless a narrowly audited exception exists.

Why approval prompts degrade in real teams
Approval fatigue follows the same curve as alert fatigue in monitoring systems. If every event is "high priority," nothing is high priority. Engineers quickly learn that most prompts are routine and begin approving reflexively, which converts "human in the loop" into theater.
Then productivity pressure takes over. If an agent needs approval for every file edit, every npm install, every test run, every git commit, and every MCP call, the workflow becomes slower than doing the task manually. Teams react predictably: they loosen controls globally or switch to permissive modes that skip checks.
That's the dangerous pivot point. Once teams disable noisy prompts, they often remove the only control they had. Suddenly the same agent that used to require five approvals can write broadly, push branches, and invoke external tools with little or no friction. The model didn't become safer; humans just stopped paying attention.
The fix is not "more prompts," and it's not "better prompt wording." The fix is always-on runtime policy enforcement that is consistent, context-aware, and independent of human attention span. Humans should approve only where judgment is truly required, like deployment-class changes and exceptional break-glass paths.
Autonomy levels vs authorization policy
Autonomy levels and authorization policy solve different problems, and confusing them is where many teams get burned. Autonomy levels are coarse configuration choices that define how much an agent can generally attempt to do by default. Authorization policy decides whether a specific action right now is permitted in context.
Think of autonomy level like cruise control and authorization policy like traffic enforcement plus road rules. Cruise control can set your operating mode, but it does not decide whether you may drive into a restricted lane, cross a red light, or enter a secure facility. You still need runtime rules that evaluate current conditions.
In practice, settings like suggest/auto/auto-full are useful but insufficient because they are blunt instruments. They do not naturally capture who triggered the run, whether the repo is production-critical, whether the target is staging or production, or whether the declared intent is refactor versus incident response. That is why autonomy levels are necessary but not sufficient: they reduce operational friction, but they do not deliver robust least-privilege enforcement on their own.
 vs authorization policy (runtime, context-aware decisioning)")
Enforcing trust levels at runtime with Permit.io
This is where Permit.io should sit in the architecture: as the runtime enforcement layer that turns autonomy settings into auditable authorization decisions. The Permit.io AI authorization approach and Permit.io documentation describe the components needed to do this cleanly.
With a Permit MCP Gateway, agent tool calls are evaluated before execution. The gateway acts as policy and routing control between agents and MCP tools, while a PDP (Policy Decision Point) returns ALLOW, conditional ALLOW, JIT approval requirement, or DENY based on context. OPAL keeps policy data and context synchronized so decisions are current at runtime.
A practical mapping looks like this:
- Read-only → ALLOW by default for approved roles and repos.
- Write-safe → ALLOW with constraints (sandbox/dev only, command allowlist).
- Privileged-write → ALLOW with conditions (protected branch rules, repo sensitivity checks, environment gating).
- Deployment-class → Require JIT approval with time-bound grant and full audit trail.
- Destructive/credentials → DENY by default; explicit override policy only for break-glass workflows.
The key is that decisions include all five dimensions: tool risk tier, human role, repo sensitivity, target environment, and agent intent. That gives you precision without turning daily work into a click-fest.
The secure rollout ladder
Most teams should implement this as a staged rollout, not a switch flip. Going from "manual everything" to "full auto" is exactly how controls collapse.
Start with read-only auto, manual for everything else.
Let agents explore and summarize freely, but gate writes while you build baseline policy visibility and audit logs.
Enable write-safe auto only in local sandbox or low-sensitivity repos.
Allow file edits, test runs, and commits under constrained conditions, using explicit command allowlist rules and narrow scope.
Introduce privileged-write with strict branch and repo controls.
Permit branch pushes and PR creation only on approved paths, with command denylist protection for dangerous command families.
Gate deployment-class actions behind JIT approval.
Keep deployment, migration, scaling, and external notification operations time-bound and explicitly approved per run.
Keep destructive and credential actions auto-denied by policy.
Do not normalize these in autonomous flows. Require documented exception procedures, dual control where applicable, and full forensic logging.
This ladder works across Cursor, Claude Code, Factory Droid, OpenCode, and mixed MCP stacks because it is based on action risk, not brand-specific UX toggles.

Frequently asked questions
Which MCP tools should require human approval?
Any MCP tool that performs deployment-class or destructive/credential operations should require JIT approval or be set to default deny. Read-only tools and many write-safe tools can run automatically under policy constraints, but the key is classifying each tool individually rather than trusting the server as a whole. MCP servers regularly bundle tools across multiple risk tiers, which means per-server allowlisting misses the distinction between a low-risk search tool and a high-risk database-mutation tool on the same server.
Is an autonomy level like "auto-full" ever enough by itself?
It is a useful configuration convenience, but it is not a security boundary. Autonomy levels define operational defaults — how aggressively the agent runs — not authorization policy. They cannot evaluate who triggered the run, what repo is involved, which environment is targeted, or what the declared intent is. Without runtime policy, auto-full is effectively a blanket permission that looks like control but isn't.
How do command allowlists and denylists fit into this model?
They are enforcement primitives inside the broader policy, not the policy itself. Allowlists should cover low-risk, high-frequency commands that are safe to run automatically in narrow contexts. Denylists should permanently block known dangerous or out-of-scope commands. The limitation of both is that they are static: they can't adapt to context like environment, role, or intent the way runtime authorization policy can.
What is the biggest mistake teams make when securing coding agents?
Treating all agent actions as equivalent and relying on prompt approvals as the primary control mechanism. That combination guarantees the disable-by-noise failure mode: approvals become noise, developers disable them, and the agent runs with zero oversight. The correct approach is granular trust levels plus always-on runtime policy that applies selective friction rather than universal friction.
Where do PDP and OPAL matter in day-to-day agent operations?
The PDP makes real-time allow/deny decisions for each attempted action, and OPAL ensures the PDP has fresh context and policy data as roles, repos, and environments change. Together they keep enforcement accurate without requiring manual policy reloads or configuration changes when team membership or repository sensitivity shifts.
Can runtime policy work without slowing developers down noticeably?
Yes, if low-risk actions are auto-allowed and only medium-to-high-risk actions trigger conditions or JIT approval. The goal is selective friction at trust-tier boundaries, not universal friction on every action. In practice, read-only and most write-safe operations run without any interruption, while only privileged-write and above encounter policy gates.
How should teams handle emergency incident response with autonomous agents?
Predefine incident-specific policies with narrow scope, short expiry, and strong auditability. Even in incidents, destructive and credential-heavy actions should remain tightly controlled with explicit accountability tied to the on-call engineer who activated the incident context. Time-bounded JIT approval with forced logging is the right mechanism — not blanket emergency bypass.